| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 풀다운저항
- leetcode
- Floating
- Softmax
- backward pass
- 풀업저항
- Features
- assignment1
- impl
- neural net
- atmega128
- pulldown
- pyTorch
- #9
- Circuit
- assignment
- NotFoundError
- palindrome
- Backpropagation
- autoencoder
- error
- pullup
- Solution
- 회로
- softmax backpropagation
- Big size image
- TensorFlow
- KNN
- two-layer neural net
- cs231n
- Today
- Total
코딩공부
cs231n assignment1 - knn 본문
글을 작성하기에 앞서 Ubuntu 환경에서 진행하였으며 anaconda와 같은 가상환경은 사용하지 않았다.
cs231n의 강의를듣고 assignment1의 knn과제를 진행하였다.
numpy에서 익숙치않은 함수들도 나와서 모두 이해하느라 어제부터 오늘까지 약 8시간은 걸린 것 같다.
knn.ipynb파일과 k-nearest-neighbor.py파일은 https://github.com/Lee-daeho/cs231n/tree/master/assignment1 에 가면 확인할 수 있다.
블로그에서는 전체 내용이 아닌 일부분들을 번역하며 설명할 예정이니 전체 파일은 github에서 확인하기 바란다.
cs231n의 assignment는 전체 코드의 일부분을 학생이 직접 코딩하여 전체 프로그램을 완성시키는 방식이다. 어느부분을 작성해야 하는지는 아래 사진과같이 나타나 있다.
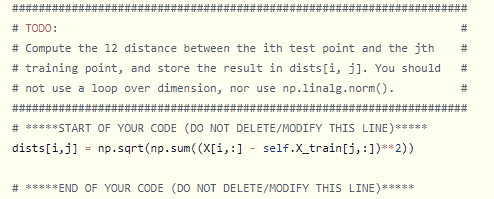
knn.ipynb와 k-nearest-nighbor.py 두개의 파일에서 코딩을 직접 해야하며 힌트도 제공하고 있다.

설명에 나와있듯이 cs231n/classifiers폴더에 있는 k_nearest_neighbor.py 파일의 compute_distances_two_loops 함수의 일부를 작성해야 한다.

함수의 이름대로 두개의 loop를 이용하여 L2 distance를 구하는 코드를 작성해야한다. 강의를 보았다면, numpy의 함수들에 대해 조금 알고 있다면 문제없이 작성할 수 있다.

위에 보는것처럼 assignment는 이런 Inline Question도 제공하고 있다. structured patterns in distance matrix는 위에 보이는 pattern이다. 데이터의 어떤것들이 밝은 열과 행을 만드냐에 대한 질문인데. 해당 pattern은 data들의 distances를 나타낸 그래프이다. 즉, 밝은 행의경우 하나의 test image가 train image들과 크게 다를 때(distance가 클때) 나타나고, 밝은 열의 경우 하나의 train image가 test image들과 크게 다를 때(distance가 클 때) 나타난다.

이후 dists를 기반으로 label을 predict하게하는데 k_nearest_nighbor.py 파일에서 predict_label 함수를 작성해야 한다.
다음과 같이 predict_label 함수를 수정하고 나면 위에 보는것처럼 27%정도의 accuracy를 확인할 수 있을것이다.

그리고 두번째 inline question이다.

이 문제는 1,2,3,4,5중 어떤 preprocessing을 하였을때 L1 distance를 이용한 Nearest Neighbor classifier가 영향을 받지 않는가에 대한 질문이다.
정답을 1,3번이라고 적었는데 마지막줄에서 볼 수 있듯이 올바른 답인지는 확인하지 못하였다.
우선 생각한대로 설명을 해보자면,
1번의 경우 전체의 평균을 각 이미지의 픽셀에서 빼주는 경우이다. 이때 모든 픽셀들이 같은 방향, 같은 양만큼 움직이므로 이후 어떤 지점에서 L1 distance를 구할 때 영향을 주지 않을 것이라고 생각하였다.
2번은 각 픽셀의 평균을 각 이미지의 픽셀에서 빼주는 것인데 이때에는 픽셀별로 평균값들이 다를것이고 즉, 픽셀들이 다른 방향, 다른 양 만큼 움직이게 될 것이므로 어느 위치에서 distance를 구함에 있어 차이가 생길것이라고 예상하였다.
3번과 4번은 1,2번과 같은 이유로 3번을 정답으로 택했다.
5번의 경우 Explanation에 쓰여있듯이 데이터의 축이 90도의 배수만큼 회전할 때에는 관계가 없지만, 그 외의 경우에는 어느 한 점에서의 거리가 회전할때 변화하게 된다. L1 distance는 x축과 y축, 각 축에서의 거리를 합한 것이기 때문에 차이가 발생한다. L2 distance의 경우 회전에 관계없이 distance는 일정하다.

이후 k_nearest_nighbor.py 파일에서 compute_distances_one_loop 함수와 compute_distances_no_loops 함수의 빈 부분을 작성해야 한다.

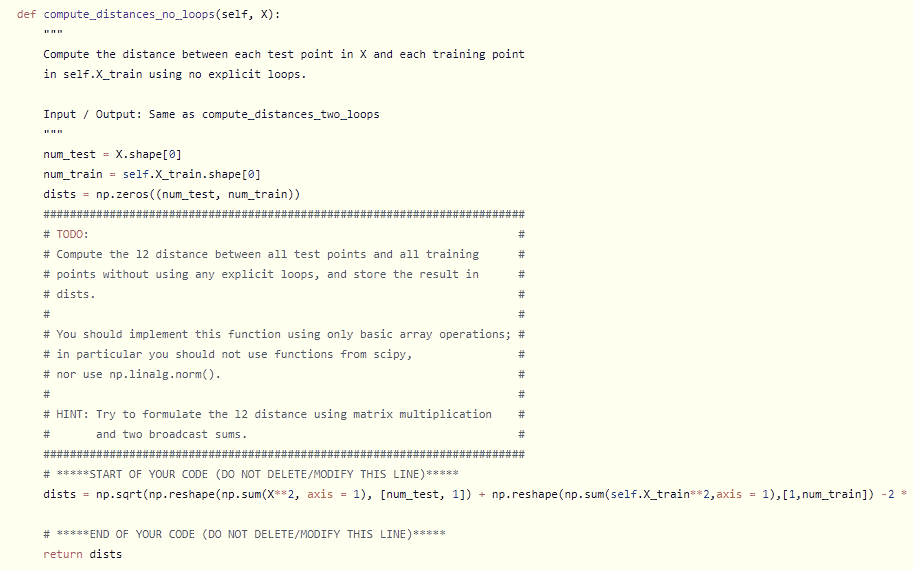
이름대로 한개의 loop를 사용하는, loop를 사용하지 않는 distance compute방법을 구현하는 부분이다.
vecterization과 numpy의 broadcasting rule을 이용하여 코드를 작성한다.
no loop함수의 뒷부분이 잘렸는데
dists = np.sqrt(np.reshape(np.sum(X**2, axis = 1), [num_test, 1]) + np.reshape(np.sum(self.X_train**2,axis = 1),[1,num_train]) -2 * np.matmul(X,self.X_train.T)) 이것이 전체 코드이다.
해당 코드의 구조를 이해하기 위해서는 L2 distance의 수식을 먼저 알아야 한다. L2 distance는 Euclidean distance라고 하며 다음과 같이 표현될 수 있다.
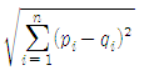
내부의 제곱을 풀어주면 p^2 + q^2 - 2 * p * q 의 식이 나올 것이고, 이를 python에서, 행렬로 이루어진 데이터를 풀기위해 작성한 코드가 위의 코드이다.
다음으로는 cross validation을 구현하는 코드를 작성해야한다.

이 부분이 가장 어려웠는데 5개의 fold로 image들을 나눈 뒤 5개의 fold를 한번씩 validation fold로 지정하여 가장 적합한 hyperparameter, k를 알아내는 코드이다. 5개의 fold중 한개를 제외한 4개의 fold를 concatenate와 list comprehension을 이용하여 x,y 두개의 행렬로 만들고 train 시켜준다. 이후 남겨두었던 validation fold로 test를 진행하여 accuracy를 각각 구한다. 이를 k_choices에서 1 ~ 100까지 10개의 값을 이용하여 계산한 뒤 모두 k_to_accuracies 배열에 저장하는 코드이다.
이후 구해낸 accuracy들에서 accuracy mean을 구하고 그중 가장 높은 accuracy를 찾는 부분이 있는데 해당 부분은 매우 간단하므로 생략하겠다.
마지막으로 Inline Question 3 이다.

다음중 k-Nearest Neighbor 방법에서 모든 k에 대해 옳은것들을 고르는 문제이다.
k-NN classifier의 decision boundary는 linear하지 않다. k-NN classifier의 decision boundary는 data간의 distance에 의해 결정되는데 같은 label의 이미지라 하더라도, car label의 이미지들이라고 하자, 임의의 이미지가 모든 train image들에 대해 같은 비율의 distance를 가질 수는 없다. 그러므로 1번은 틀렸다.
2번의 경우 training error란 training 하는데 사용했던 data를 다시 trained model에 적용시키는 것을 의미하는데 1-NN의 경우 model에서 자기자신을 발견할 것이고 이경우 distance는 0이 될 것이다. 5-NN의 경우 자기자신 이외의 이미지를 발견할 수 있으므로 distance가 0이라는것을 확신할 수 없다. 그러므로 1-NN의 error가 항상 5-NN보다 작다.
test error는 training error와 다르게 새로운 이미지들을 사용하므로 problem dependent, 즉, 문제에따라 1-NN이 error가 더 작을수도, 5-NN이 더 작을수도, 같을수도 있다. 그러므로 3번 또한 오답이다.
4번은 강의에서 잘 설명이 되어있듯이 k-NN claissfier는 predict를 할때 모든 training set에서 distance를 구한다. 즉, training set의 크기가 커지면 distance를 구해야 할 대상이 늘어나므로 시간이 더 필요하게 된다.
공부를 하는중인 학생이고 위의 코드와 Inline Question들은 직접 푼 것들이기 때문에 실제 정답과 차이가 있을 수 있습니다.
코드 혹은 Inline Question의 Answer에 대해 의문이 들거나 틀린 부분을 발견하신다면 댓글로 알려주시면 감사하겠습니다. 건설적인 토론도 항상 환영입니다.
코드 및 사진 출처 - cs231n.github.io
'ML , DL (2019) > cs231n' 카테고리의 다른 글
| cs231n assignment1 - two-layer neural net (0) | 2020.01.10 |
|---|---|
| backpropagation, intuition - 2 (요약) (0) | 2019.09.01 |
| Backpropagation, Intuitions (0) | 2019.08.22 |
| assignment1 - softmax (0) | 2019.08.20 |
| cs231n assignment1 - SVM (0) | 2019.08.17 |



