| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- pulldown
- pullup
- Circuit
- Floating
- leetcode
- impl
- assignment1
- 풀업저항
- error
- Big size image
- Solution
- Softmax
- 회로
- softmax backpropagation
- palindrome
- pyTorch
- two-layer neural net
- TensorFlow
- backward pass
- atmega128
- Features
- Backpropagation
- assignment
- cs231n
- autoencoder
- #9
- 풀다운저항
- NotFoundError
- neural net
- KNN
- Today
- Total
코딩공부
Joint Learning of Saliency Detection and Weakly Supervised Semantic Segmentation 본문
Joint Learning of Saliency Detection and Weakly Supervised Semantic Segmentation
초보코더 2019. 12. 26. 19:31Yu Zeng et.al.
이번 논문은 Saliency Detection과 Weakly Supervised Semantic Segmentation을 2-stage model을 만들어 결합시킨 형태의 model에 관한 논문이다. Saliency Detection은 이미지로 부터 가장 관심이 가는 부분을 extract하는 방법이고 Weakly Supervised Semantic Segmentation(WSSS)은 이미지로부터 물체의 위치(pixel)을 extract하는데 이때 bounding box와 같은 불완전한 Label을 이용하는 방법이다.
기존에도 두가지 이론을 동시에 활용하는 방법은 존재 하였으나 본 논문의 가장 큰 차이점은 크게 두가지로 첫째는, 기존의 WSSS방법들은 pre-trained saliency detection model을 활용한 반면, 본 논문의 방법은 end-to-end 방식을 이용한다는 것. 둘째는, saliency detection이 기존에는 segmentation을 위한 pre-processing step이였다면 본 논문에서는 SD와 WSSS를 동시에 진행된다는 것이다.

본 논문의 Overview는 Figure 2에 설명되어 있다. 큰 특징으로는 fully connected classifier를 사용하지 않고 convolutional block을 사용하여 feature를 extract하였다는 것과 큰 feature map을 얻기위해 downsampling operator를 제거하고 dilated convolution을 하였다는 것이다.
본 논문의 모델은 2개의 stage, SSNet-1과 SSNet-2로 이루어져 있으며 두 stage 모두 Segmentation Network(SN)과 Saliency aggregation module(SAM)으로 이루어져 있다.
SSNet-1은 pixel-level의 saliency annotations와 image-level의 semantic category labels를 기반으로 train되고, SSNet-2는 saliency annotations와 image-level의 semantic category labels를 기반으로 train된다. SSNet-2의 semantic category labels는 SSNet-1의 segmentation result이다. 이에 대해서는 Figure 2에 전체적인 구조가 설명되어 있다.
각각의 stage와 Network들에 대해 더 자세히 알아보면, SSNet-1에서는 간단한 structure를 사용하여(i.e. 1 x 1 convolution layer) image의 모든 pixel에 class별로 0또는 1의 값을 부여하는 방식으로 segmentation result를 얻어낸다. 이 result를 바탕으로 SSNet-2는 dilation rate가 6,12,18,24의 4개의 3 x 3 convolution layers를 사용하여 결과의 합을 segmentation result로 얻는다. SSNet-2의 Segmentation방법은 "Deeplab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs" 논문에서 제시한 방법이다.

SAM은 SN이 pixel-level의 saliency labels를 이용하여 더 정교한 segmentation result를 만들수 있도록 설계되었다. 식 1. 에서 볼 수 있듯이 category별 saliency score와 segmentation result를 곱하여 더하는 방식으로 weighted sum을 구해낸다. 식에서 S는 Saliency map, vi는 i번째 category의 Saliency score, Hi는 i번째 category의 공간분포에 대한 segmentation result이다.


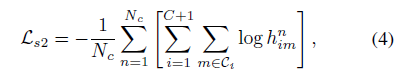
Loss의 경우 cross entropy방식을 주로 사용하여 구해내고 image-level의 category labels에 대한 loss, saliency ground-truth에 관한 loss를 적절히 합하여 SSNet-1과 SSNet-2의 loss를 각각 구해낸다.
식 1에서 나온 Lc는, segmentation result과 ground-truth category labels에 관한 loss로, t(n,i)는 0또는 1의 값을 가지며, n번째 이미지가 i번째 category의 object를 포함하고 있는지를 나타낸다. tn은 one-hot encoding이다.
Ls1은 saliency map과 saliency ground-truth에 관한 loss로, y(n,m)은 0또는 1의 값을 가지며, n번째 이미지의 m번째 pixel의 saliency ground-truth 값을 나타내고, s(n,m)은 0~1의 값을 가지며, n번째 이미지의 m번째 pixel의 saliency map 값을 나타낸다.
Ls2는 segmentation result와 pseudo label에 관한 loss로, h(n,im)은 0~1의 값을 가지며, n번째 이미지의 m번째 픽셀이 i번째 class를 포함하고 있을 확률을 나타낸다.
SSNet-1의 loss는 Lc + Ls1를, SSNet-2의 loss는 Ls1+Ls2를 이용한다.
결과적으로 기존의 방법들보다 나은 성능을 보인다는 것을 실험을 통해 증명했으며, 본 논문의 방법을 SSNet-1과 SSNet-2를 각각 나누어 진행한 것 보다 두개의 stage가 논문에 소개된 방법으로 연결되어 진행할 때 가장 좋은 성능을 보인다고 결론짓고있다.
본 논문을 읽으며 새로운 개념과 방법론에 대해 많이 배울 수 있었다. 논문의 수준이 높아 읽고 이해하는데 긴 시간이 걸린 것 같다. 참고논문들을 찾아보며 흥미로운 주제를 가진 논문들도 많이 알 수 있었다. 그러나 현재 본인의 수준에서 너무 수준이 높은 논문을 읽는 것은 시간대비 효율이 좋지 못하다고 판단되어 기술의 application보다는 기초적인 내용의 논문들을 찾아 읽어보는 것이 나을 것 같다.
pseudo label이, CAM, Saliency Detection, Semantic Segmentation등에 대해서 추후에 간단한 설명 자료를 만들어 볼 생각이다.
'ML , DL (2019) > 개인 생각 및 논문' 카테고리의 다른 글
| Data관련 Machine Learning 논문 용어 정리 (0) | 2021.01.09 |
|---|